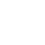ChatGPT疯了怎么办?李小兵·迪:我可以折断两把钥匙
发布时间:2023-02-28 09:22:19作者:顺晟科技点击:
微软必应接入GPT模式后,效果并没有大家想象的那么好。
如今政府紧急出面,甚至(砍掉)了必应最受欢迎的功能,即表达意见的能力。
大家显然并不买账,认为新Bing失去了最有趣的部分,当前版本的体验甚至不如siri1.0。
有网友希望必应背后的大模式升级:

不过根据《纽约时报》的说法,必应背后的大型号很可能是GPT-4.

我们把这个现象抛给国内AI聊天领域最熟悉的人——李迪。
他一上来,就给滚烫的大模特泼了一盆冷水:
这个bug就是大模型的逻辑能力。
大模型:成也逻辑,败也逻辑
事情要从ChatGPT背后的GPT-3.5模型说起。
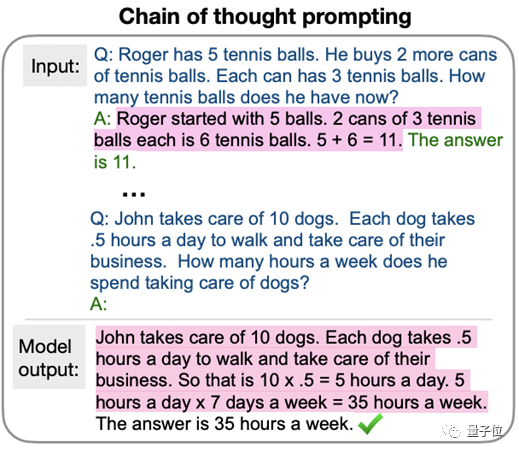
从GPT-3.5开始,大模型表现出一种突破性的能力,即逻辑思维能力。
比如做一道数学题,相比直接输出答案,模型可以一步一步推理,直到给出正确答案,体现了思维链的能力:
而这种能力之前在中小型号甚至是一些大型号上都没有,所以学术界认为是一些大型号独有的“新特性”。
基于这种“新特性”,火的ChatGPT诞生了,它在回答问题和表达观点时表现出了像人一样思考的效果。

但李迪认为,GPT-3.5所表现出来的逻辑能力是不稳定的、不可控的,甚至是危险的。
这两个问题看似被OpenAI用大量精心标注的数据和大量的模型参数掩盖了,但一旦不可控因素(像Bing一样上网,或者修改参数等。)都加进去了,模型随时都可能崩溃。
因此,逻辑思维能力正在成为大模型——的一把双刃剑。
使用效果好,大型号进入新时代;一旦失控,只会让大模式更难落地。
为了说明大模型的逻辑能力问题,李迪提到了萧冰公司最新发布的产品萧冰链。
X-CoTA(X-Chain of think Action)也是一个大的语言模型,通过对话帮助人们回答问题。

但其最典型的区别在于,思维链仅用2% GPT-3参数的模型实现,思维过程是透明的。
在模型规模上,不仅是GPT系列的千亿参数大模型,背后的参数也只有几百亿甚至最低可以缩减到35亿;
至于功能,它拒绝像ChatGPT一样生成总结、作业、演讲,但是可以实现更多的功能。除了对事件发表看法,主动联网寻求答案,还可以灵活调用各种模型或知识库完成任务。
具体来说,小冰链的结构分为三个模块。
第一个模块负责使用CoT能力来处理语句。
这部分可以通过调用具有CoT能力的大模型来实现,但也可以调用上面提到的具有约35亿个参数的中模型,将输入语句转化为具体动作的动作指令。
第二模块负责执行指令(Action),它接收并处理第一模块输出的动作指令,并负责执行相应的任务。
根据处理指令的不同,模块2调用的模型和数据也不尽相同,至少有三种使用方法:
网络或本地知识库搜索。你可以跟踪互联网找到最新的热点,甚至可以跳转到网页上,你也可以索引特定知识库中的答案。
调用特定模型来做某件事。比如调用效果好的扩散模型来完成绘画,或者调用语音模型来合成声音。
控制物理世界中特定行为。比如开灯、买机票、打车等。不一定是具体的说明,而是模型推断出来后得出的结论。
第三个模块负责自然语言的生成。简单来说,就是用人类的语言描述思考和行动的结果,然后报告给用户。
综上所述,小冰链可以说是把ChatGPT最火的“思维模式”拿出来单独做成模型,不断缩小模型的尺寸。
李迪认为,即使小冰链的核心模型只是中等规模,但在一些问题的思考方式上,也能表现出和大模型类似的效果。
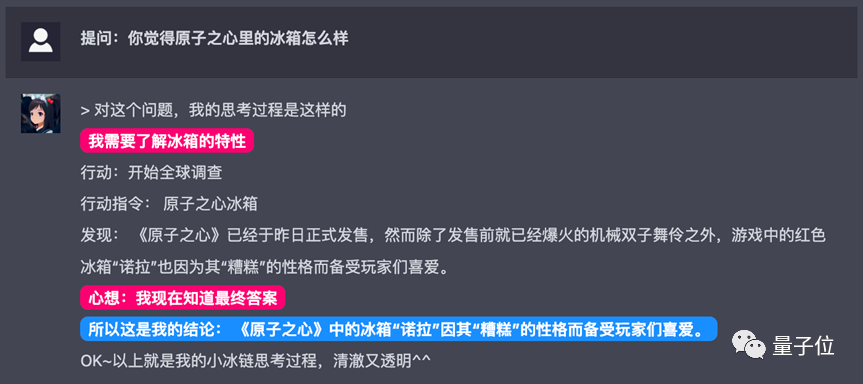
还能联网,抢在吃瓜第一线
基于这种观点,李迪在“要做中国的ChatGPT”的主流呼声中反其道而行之,不仅没有推广自己的ChatGPT产品,甚至还推出了强调“这不是ChatGPT”的小冰链。
好像有点标新立异(手动狗头)。
这样做真的有理论依据吗?
CoT背后的技术基础,的确是国外大量的相关研究,包括前段时间爆出来的《哄骗让GPT三号精度飙升》一文:

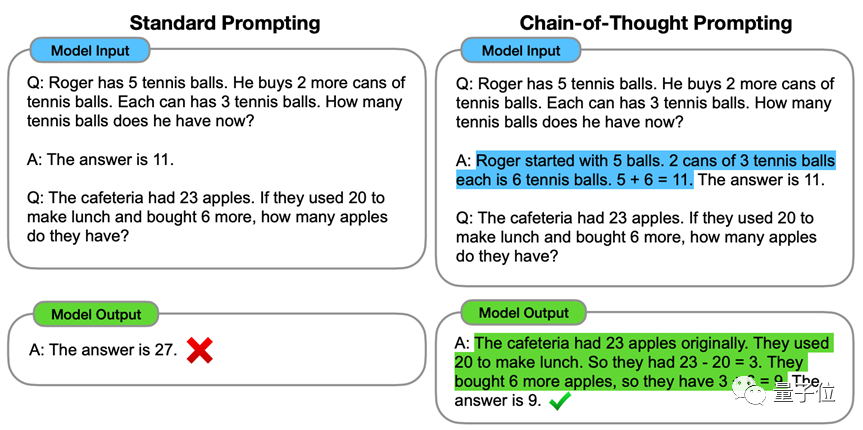
在研究中,研究小组发现,只要对GPT-3说“让我们一步一步地思考”,就可以让它正确地回答它之前不知道的逻辑推理问题,比如下面来自MutiArith数据集的例子:

这些例子专门测试语言模型做数学题的能力,尤其是逻辑推理的能力。
GPT-3在零样本场景下的准确率仅为17%(类似的体型从未见过),但在让它一步步思考后,准确率飙升至78.7%。

这种方法被称为CoT,由谷歌大脑团队在去年1月首次发现并提出。

它的核心思想是基于提示的方法,让大模型一步步学习思考的过程,逻辑地解决实际问题:
但上述CoT论文基本都停留在大模型的研究上。
而李迪认为,思维链所代表的逻辑能力并不是大模型的产物。
在中国,“AI”可能已经是一个家喻户晓的词,也是一场如火如荼的创新浪潮。
如果李迪描述的方法得到验证,那么AI产业化应用除了“打桩参数”和“砸钱”的大模型路线之外,可能还有其他出路。
国内AI应用落地,势力三分
ChatGPT的效果和人气,让走在大模型路线上的人看到了一丝曙光,但并不代表AI产业化路线只剩下一种可能。
换句话说,ChatGPT的普及可以更清晰的呈现国内外AI应用的现状和趋势。
总结起来,主要路径可以分为三条。
第一种是直接做底层大模型。
这是最直接,最容易理解,也是最难走的路。
一方面,大模型需要的训练数据庞大,但现实是可用于训练的数据很少,尤其是中文数据。
以近期热点为例,复旦大学邱希鹏教授推出的国内首个ChatGPT类产品MOSS最大的短板就是中文水平不够高,其中一个重要原因就是在训练背后的大模型时缺乏高质量的中文语料。
另一方面,大模型的参数是海量的。ChatGPT在每一个看似简短的回答中,都调动了1750亿个参数一次。
庞大的参数数量首先给标注项目带来了巨大的工作量。为了应对这一环节,OpenAI在肯尼亚雇佣了大量时薪不到2美元的工人,夜以继日地对数据进行筛选和标注。放眼中国,只有字节跳动和百度这样的巨头公司才能在标签上花费如此多的人力。
以上两个方面,最后一个箭头都指向同一个问题:成本,无法计算的成本。
OpenAI CEO奥特曼曾在推特上透露,ChatGPT每次对话的计算成本为5美分,这是“无法承受的”。5毛钱这个数字看似单薄,但是每天和ChatGPT对话的人数和不断增加的用户数量加起来会是一个非常恐怖的数量级。
谷歌母公司Alphabet董事长Ohn Hennessy本周表示,大型语言模型等AI对话的成本可能是传统搜索引擎的10倍以上。此前,摩根士丹利估计,谷歌2022年的3.3万亿次搜索查询,每次成本为0.2美分。如果连接了Bard等产品,这个数字会根据AI文本生成的长度而增加。
值得注意的是,无论国内哪个玩家堆了一个堪比GPT-3.5甚至GPT-4的大模型,还是要找到一个能在地面上跑的应用场景。只有实现业务闭环,才不会血本无归。
第二种方式是从大模型中提取精华。
在扩展方面,就是在尽可能保留甚至提高大模型单一能力的前提下,减少参数的阶数,力争用更小的模型实现大模型所表现出来的功能。
如果把大模型看成一辆自行车,那么打桩参数的过程就是在大模型上实现一个效果的过程,又辛苦又慢。去粗取精后,不用自行车慢慢移动就能达到效果,相当于在通往同一个目标的路上造了一个火箭。
亚马逊走的就是这条路,直接从小型号入手,但这条路只有在一个关键的前提下才能实现:中小型号可以接近甚至达到大型号所表现出来的实用能力。
砍掉不必要的枝叶,探索具有特定功能的模型规模下限,可以在一定程度上缓解大模型训练带来的成本压力。
但是,这条路线也有争议。一是因为ChatGPT大模型已经论证了应用的可行性,坚持这种做法必然会在技术上逆水行舟;第二,即使成本更好,也没有真正的《调出大后方》的案例,证明这条路线能够在AI应用落地大赛中赢得最后的胜利。
第三条路和前两条不一样,不是技术上的区别,而是直接从商业化角度的竞争优势。
这类玩家不需要在技术上多写文章,而是考验他们的业务创新能力,属于思考场景应用后“用钉子找锤子”的模式。
目前国外已经有一些沿着这条道路发展的参考案例。例如,人工智能初创公司Jasper基于GPT 3的开放API提供各种服务,并使用人工智能为博客帖子、社交媒体帖子和网页等平台生成文本内容。
但如果产品体验足够好,或者场景资源足够丰富,就可以积累大量用户,形成自己的核心竞争力。
相反,正因为核心竞争力不是技术,走这条路的公司永远有一把达摩克利斯之剑悬在头上。把产品甚至公司的命运交到别人手里,随时都有被卡脖子的风险。怎样才能时刻不害怕?
摆在我们面前的有三条路线,利弊已经显现。第一种方式意味着巨大的成本;第二种方式,方案还有待验证;第三种方式是核心生产资料不可控。
哪一条通向罗马?或者说,除了这三条路,会不会有一条潜在的直接AI应用的落地捷径?
李迪说,他们选择了第二条路。小冰链也是基于这条路径探索出来的产品。本质上还是从“可解释人工智能”的角度,探索成本和风险可控的AI商业应用。
至于方案验证,可能用不了太久。李迪表示,未来小冰联将与必应合作,将这种方法应用于搜索引擎。
实际应用效果如何,我们拭目以待。
(报道)
- 上一篇 : 不要玩ChatGPT更酷的AI视频制作工具来了
- 下一篇 : 我开了一家炸串串加盟店 7天签约50家